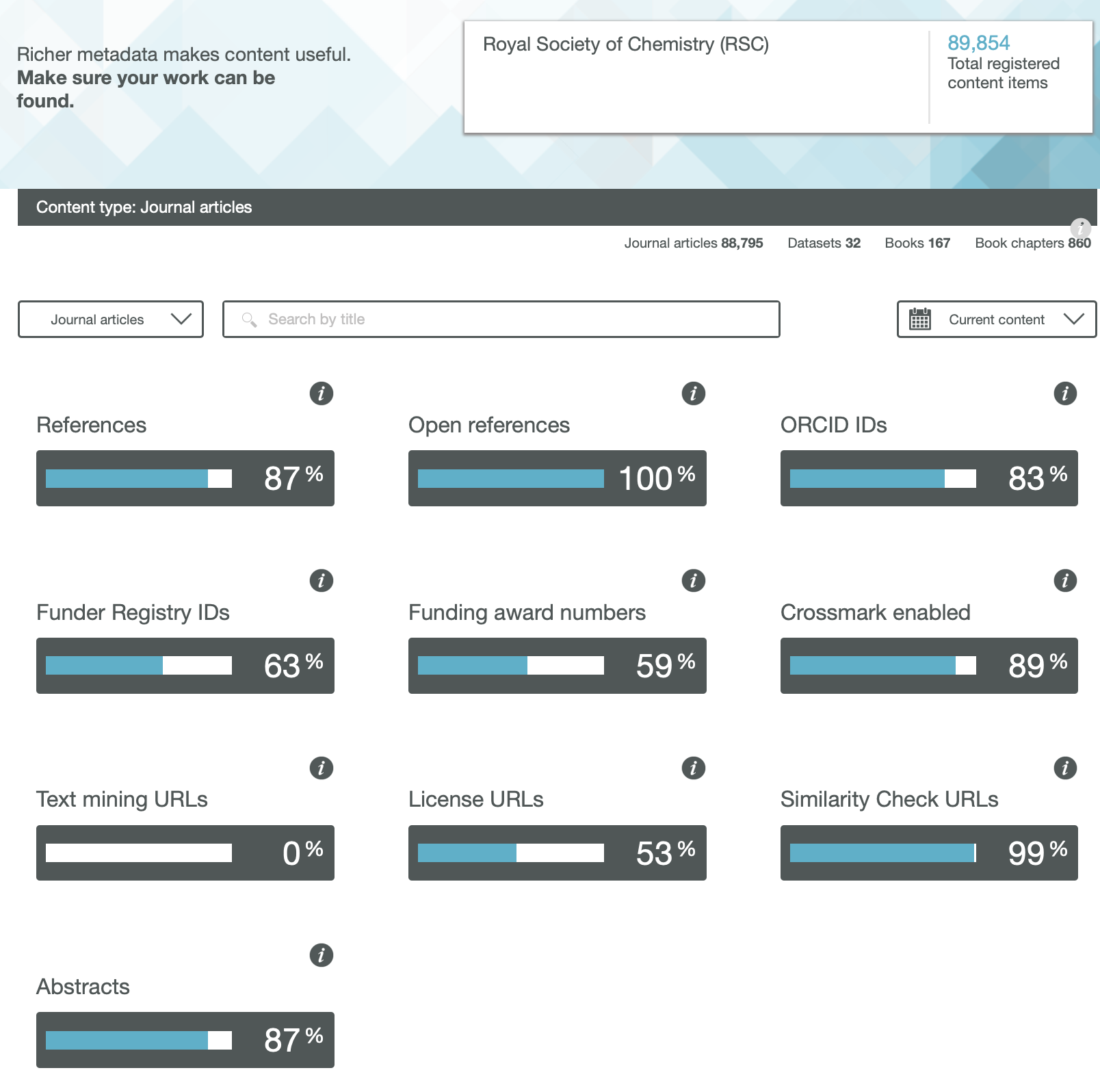
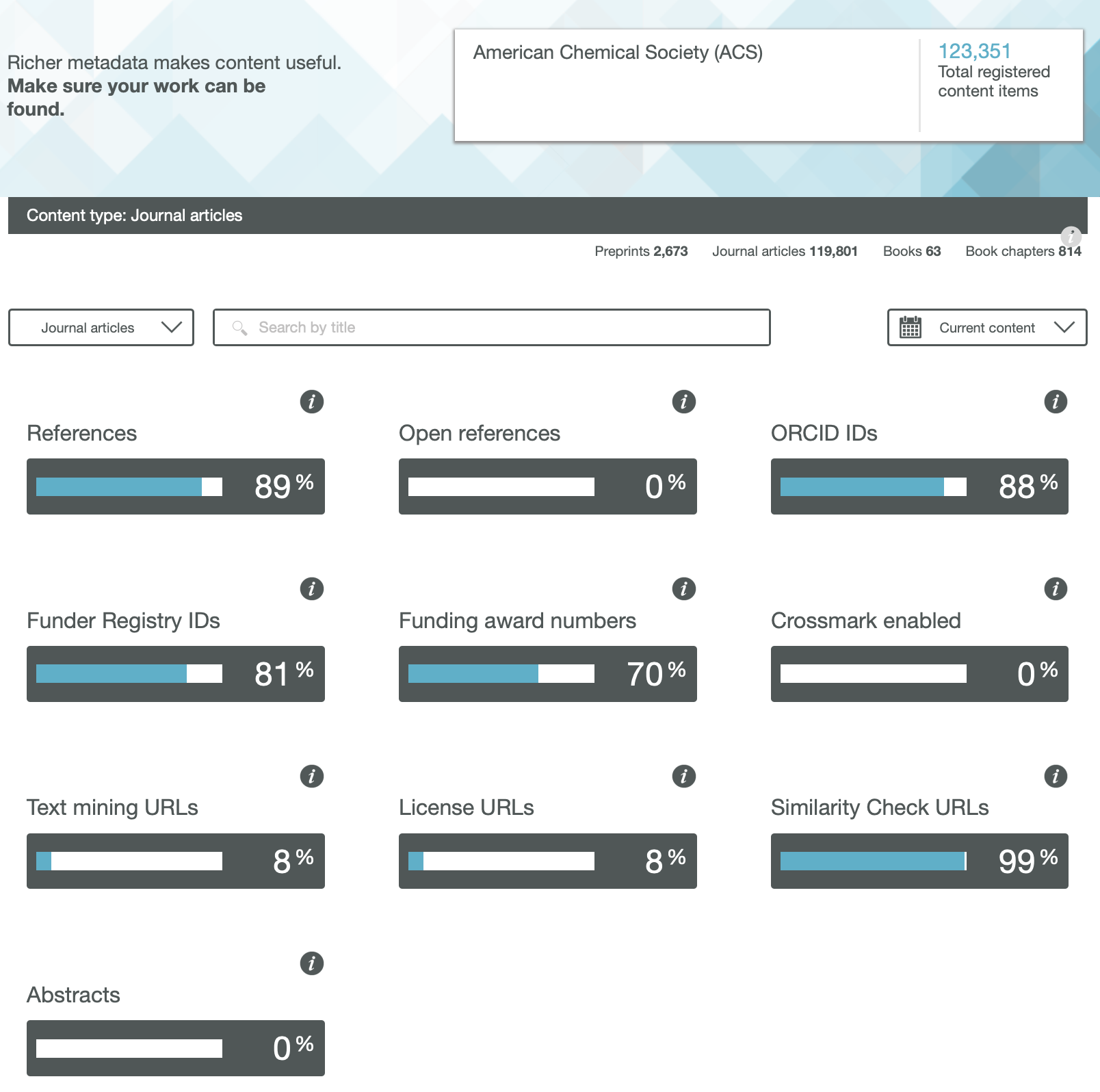
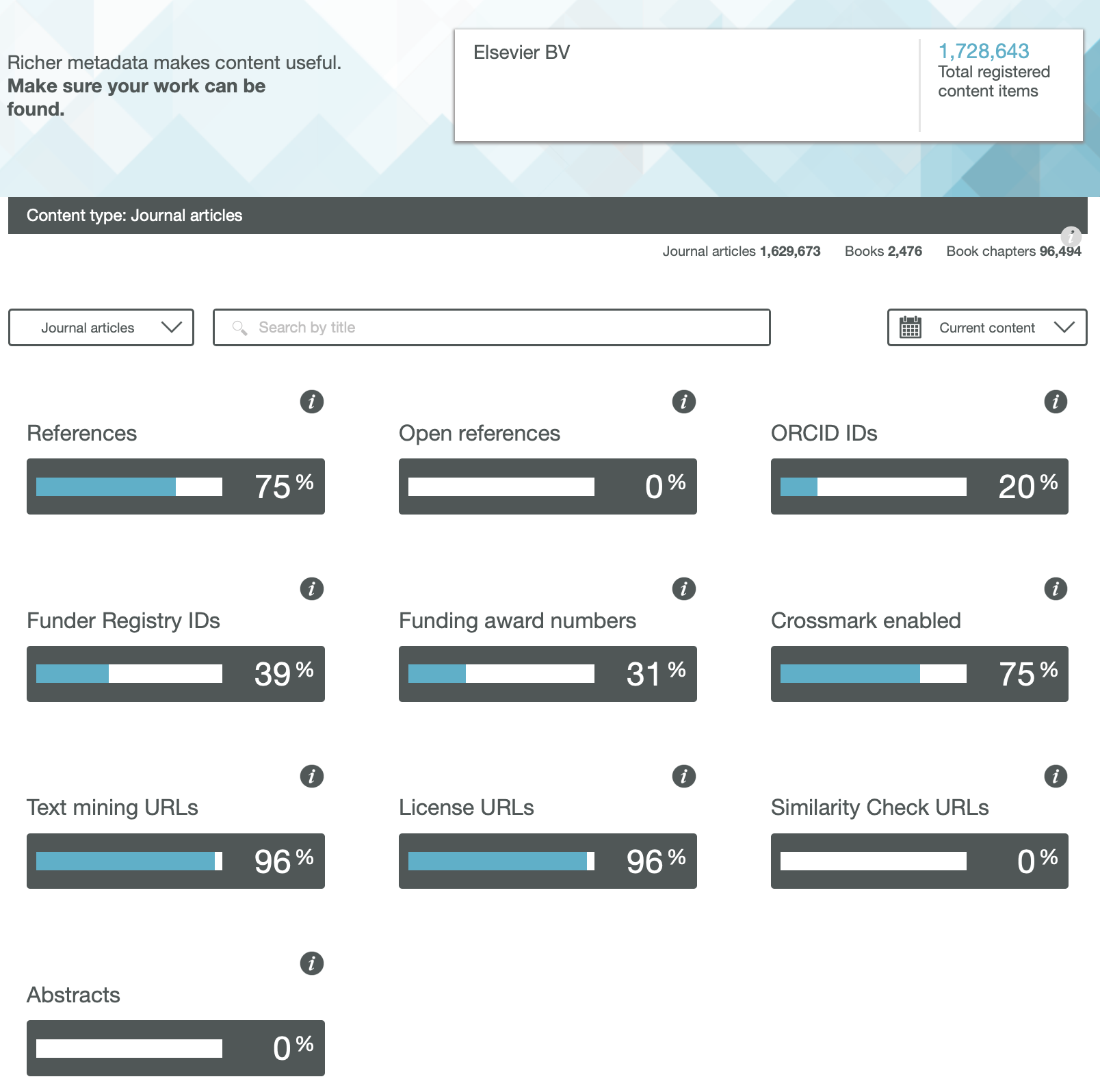
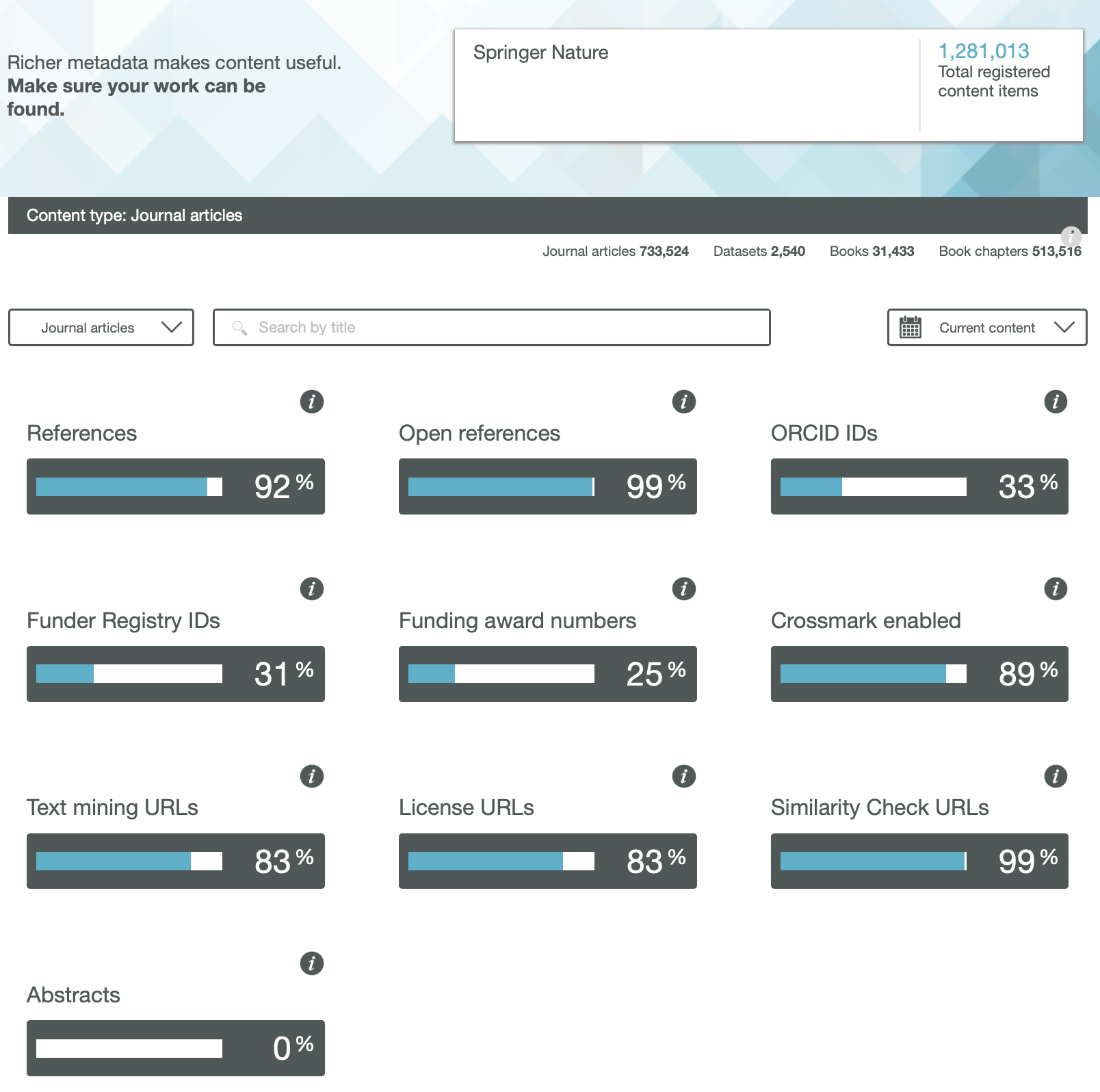
The traditional structure of the research article has been honed and perfected for over 350 years by its custodians, the publishers of scientific journals. Nowadays, for some journals at least, it might be viewed as much as a profit centre as the perfected mechanism for scientific communication. Here I take a look at the components of such articles to try to envisage its future, with the focus on molecules and chemistry.
The formula which is mostly adopted by authors when they sit down to describe their chemical discoveries is more or less as follows:
- An introduction, setting the scene for the unfolding narrative
- Results. This is where much of the data from which the narrative is derived is introduced. Such data can be presented in the form of:
- Tables
- Figures and schemes
- Numerical and logical data embedded in narrative text
- Discussion, where the models constructed from the data are illustrated and new inferences presented. Very often categories 2 and 3 are conflated into one single narrative.
- Conclusions, where everything is brought together to describe the essential aspects of the new science.
- Bibliography, where previous articles pertinent to the narrative are listed.
In the last decade or so, the management of research data has developed as a field of its own, with three phases:
- Setting out a data management plan at the start of the project, often a set of aspirations together with putative actions,
- the day-to-day management of the data as it emerges in the form of an electronic laboratory notebook (ELN),
- the publication of selected data from the ELN into a repository, together with the registration of metadata describing the properties of the data.
In the latter category, item 8 can be said to be a game-changer, a true disruptive influence on the entire process. The key aspect is that it constitutes independent publication of data to sit alongside the object constructed from 1-5. More disruption emerges from the open citations project, whereby category 5 above can be released by publishers to adopt its own separate existence. So now we see that of the five essential anatomic components of a research article, two are already starting to achieve their own independence. Clearly the re-invention of the anatomy of the research article is well under way already.
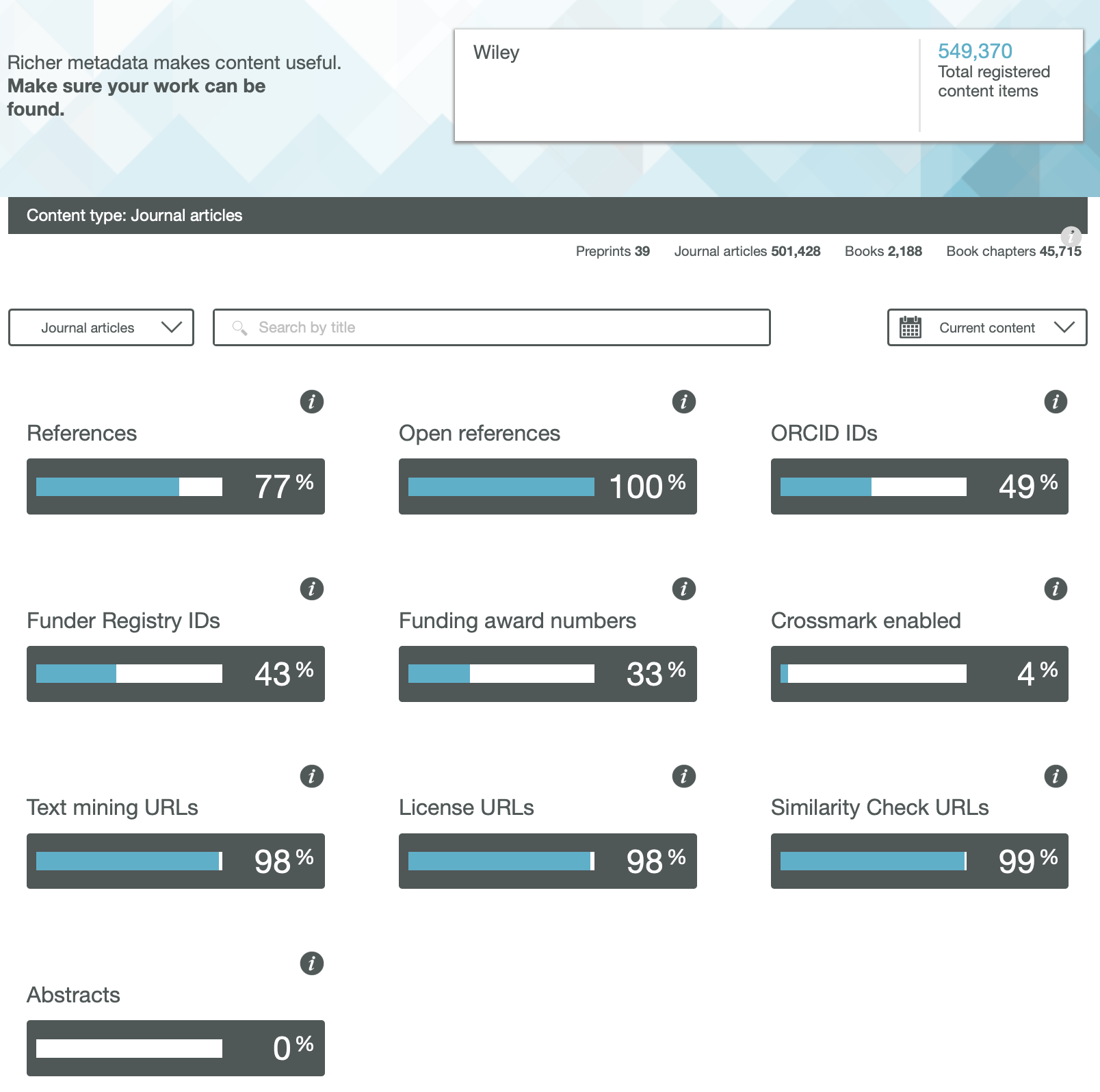
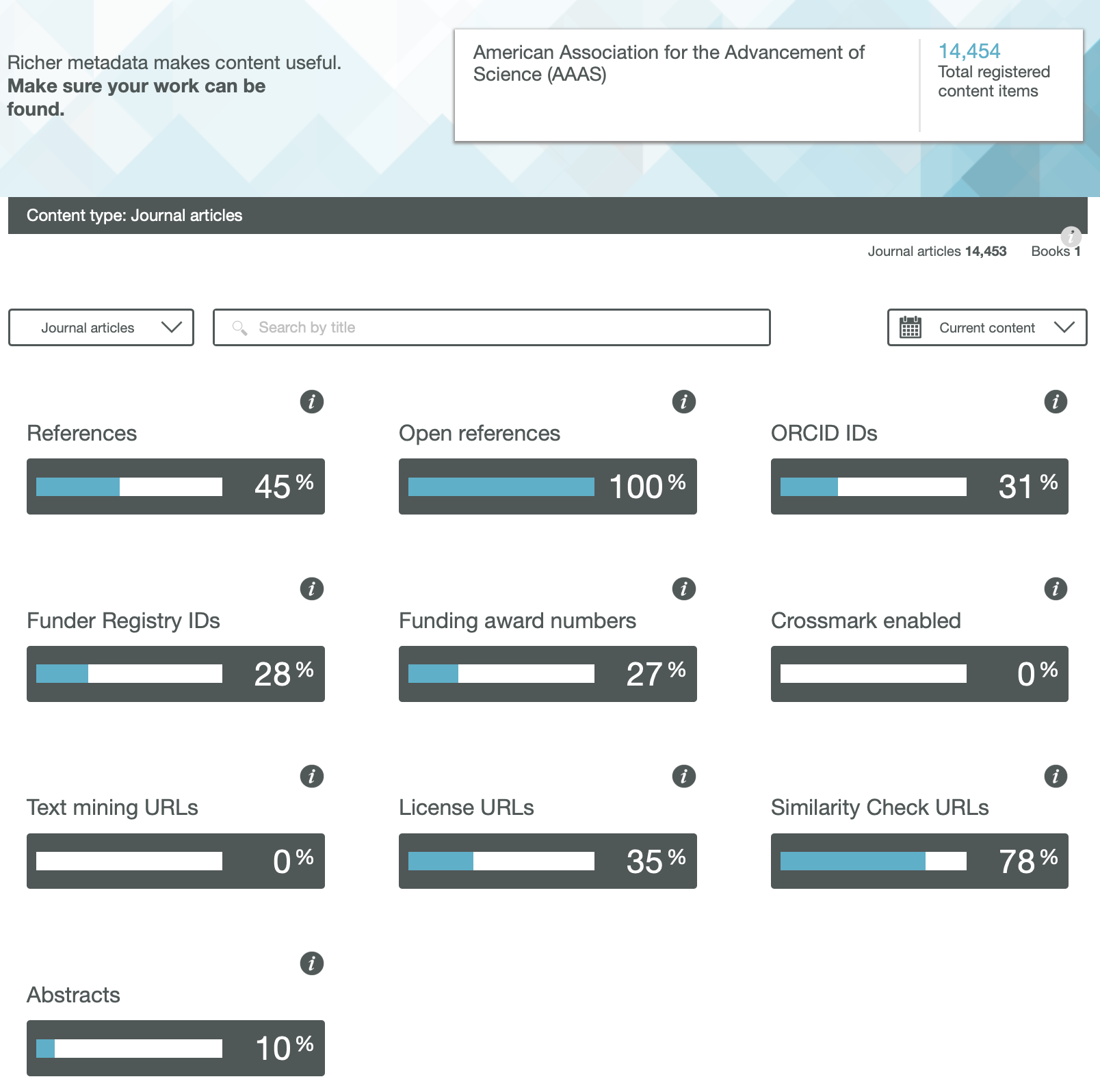
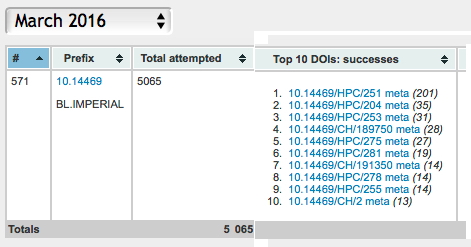
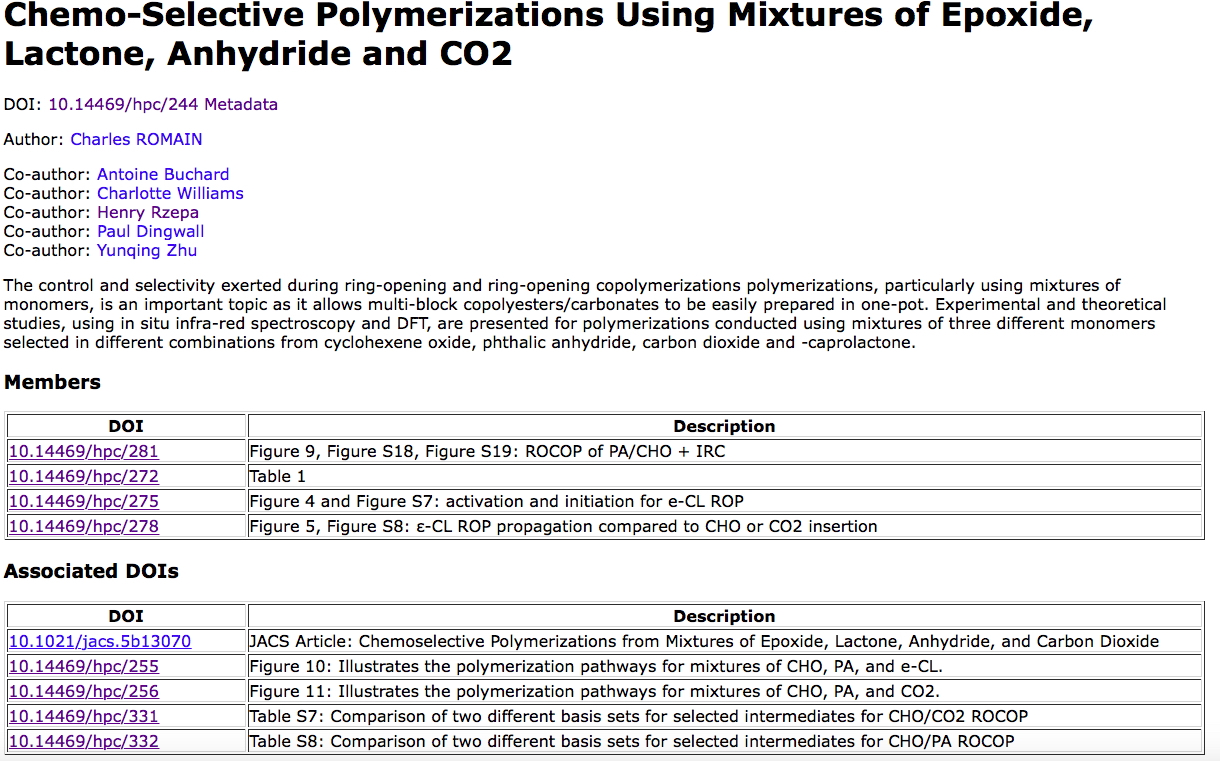
Next I take a look at what sorts of object might be found in category 8, drawing very much on our own experience of implementing 7 and 8 over the last twelve years or so. I start by observing that in 2 above, figures are perhaps the object most in need of disruptive re-invention. In the 1980s, authors were much taken by the introduction of colour as a means of conveying information within a figure more clearly; although the significant costs then had to be borne directly by these authors (and with a few journals this persists to this day). By the early 1990s, the introduction of the Web[cite]10.1039/C39940001907[/cite] offered new opportunities not only of colour but of an extra dimension (or at least the illusion of one) by means of introducing interactivity for three-dimensional models. Some examples resulting from combining figures from category 2 with 8 above are listed in the table below.
Example 1 illustrates how a figure from category 2 above can be augmented with active hyperlinks specifying the DOI of the data in category 8 from which the figure is derived, thus creating a direct and contextual connection between the research article and the research data it is based upon. These links are embedded only in the Acrobat (PDF) version of the article as part of the production process undertaken by the journal publisher. Download Figure 9 from the link here and try it for yourself or try the entire article from the journal, where more figures are so enhanced.
Example 2 takes this one stage further. The hyperlinks in the published figure in example 1 were embedded in software capable of resolving them, namely a PDF viewer. But that is all that this software allows. By relocating the hyperlink into a Web browser instead, one can add further functionality in the form of Javascripts perhaps better described as workflows (supported by browsers but not supported by Acrobat). There are three such workflows in example 2.
- The first uses an image map to associate a region of the figure data object defined by a DOI.
- The second interrogates the metadata specifically associated with the DOI (the same DOIs that are seen in the figure itself) to see if there is any so-called ORE metadata available (ORE= Object Re-use and Exchange). If there is, it uses this information to retrieve the data itself and pass it through to
- the third workflow represented by a set of JavaScripts known as JSmol. These interpret the data received and construct an interactive visual 3D molecular model representing the retrieved data.
All this additional workflowed activity is implemented in a data repository. It is not impossible that it could also be implemented at the journal publisher end of things, but it is an action that would have to be supported by multiple publishers. Arguably this sort of enhancement is far better suited and more easily implemented by a specialised data publisher, i.e. a data repository.
Example 3 does the same thing for a table.
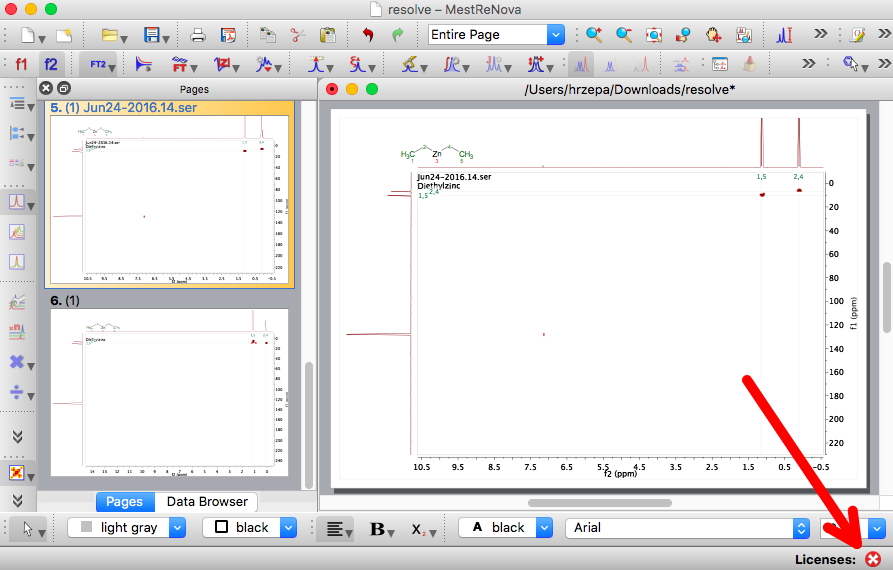
Example 4 enhances in a different manner. Conventionally NMR data is added to the supporting information file associated with a journal article, but such data is already heavily processed and interpreted. The raw instrumental data is never submitted to the journal and is pretty much always possibly only available by direct request from the original researchers (at least if the request is made whilst the original researchers are still contactable!). The data repository provides a new mechanism for making such raw instrumental (and indeed computational) data an integral part of the scientific process.
Example 5 shows how a bibliography can be linked to a secondary bibliography (citations 35 and 36 in this example in the narrative article) and perhaps in the future to Open Citations semantic searches for further cross references.
So by deconstructing the components of the standard scientific article, re-assembling some of them in a better-suited environment and then linking the two sets of components to each other, one can start to re-invent the genre and hopefully add more tools for researchers to use to benefit their basic research processes. The scope for innovation seems considerable. The issue of course is (a) whether publishers see this as a viable business model or whether they instead wish to protect their current model of the research article and whether (b) authors wish to undertake the learning curve and additional effort to go in this direction. As I have noted before, the current model is deficient in various ways; I do not think it can continue without significant reinvention for much longer. And I have to ask that if reinvention does emerge, will science be the prime beneficiary?